![[PukiWiki]](image/pukiwiki.png "[PukiWiki]")
参考書。いわゆるパタヘネ本。
物理的制約のもとで複数のシステムを有機的に組み合わせ,計測,認識,制御,知能などを実現する最適化されたインタラクティブな計算システムの構成理論と手法を学ぶ。
Presented by sen. tzik all blame reserved.
誤植は見つけた人が直すものです
iii.までがソフト屋さんの仕事。ここが変わるとソフト、ハード両面に影響が出るので設計はとても重要。
ivはレジスタ間の転送をハードウェアで実現する手法を規定
VHDL,Verilogとかのハードウェア記述言語を使う。
データパスと制御論理
v.は第一でやったところ
vi.はトランジスタの話。基本的にはこのあたりを気にする必要はあんまりない。
RISC(Reduced insttuction set computer)
→ハードウェアで実現する機能、命令は簡単なものでも良い。
プログラムの実行時間=(プログラムあたりの命令数)*(1命令あたりの実行時間)
高級言語マシンでは、1↓ 2↑
RISCでは1↑2↓
RISCでは単純な命令だけにして命令セットの数を減らすのが目的→複雑な動作をするためには命令数が増えるが、一つ一つの命令を早くすることで解決する
'(1命令あたりの実行時間) = (1命令あたりの所要サイクル数)*(サイクル時間)'
単純な命令を繰り返すもののほうが、流れ作業に向いている。面倒なのでウィキペとか参考書とかを参照(パイプライン処理)
2.命令セットアーキテクチャ 2.1命令(instruction) PUが処理すべき動作を指示
命令セットアーキテクチャ(instruction set architecture)
→命令の体系、ハードウェアとソフトウェアのインターフェイス、計算機構成の重要な抽象化レベル
命令の種類
命令語(instruction words)
命令を表現するword(バイナリ)
MIPSの命令については、これが分かりやすいかも
http://ocw.kyushu-u.ac.jp/0009/0006/lecture/10.pdf
2.2 主記憶のアドレシング
PUのレジスタは数十個(MIPSの場合は32ないし64個)なので、メモリからデータを読みこむ必要がある。図はめどいので教科書とかを参考。
アドレス付けの単位
主記憶のサイズ
プリント2^32=2^32バイト(32bitアドレス空間) →4GB
最近はこれじゃ足りないので、64bitアドレス空間を使っているもの増えてきた。
命令セットアーキテクチャ
プロセッサAからプロセッサBへ。
今までのソフトウェアが動くか?
そもそも同じなら、完全互換。命令を追加した場合は上位互換。Intelのx86は、上位互換を維持するために、複雑怪奇な命令セットになっているのだとか…
エンディアン(Endian)
命令セットの違いはソフトウェア側でなんとかなる。でも、アドレスづけの単位やらエンディアンの違いは、どうにもならないこともある。
2.3命令セットアーキテクチャの分類 用意されているオペレーション(操作)の種類による分類ではなく、利用できるオペランド(操作対象)に大きく依存
2.3.1 PU内部の記憶部
詳細はググれカス(by 中村先生)
4/28
2.3.2 汎用レジスタ方式における記憶部の指定方法
(1)regiaster addressing
レジスタを指定する
add r1,r2,r3 # r1 <= r2 + r3
(2)immediate addressing(直値)
オペランドの値を指定する
add r1,r2,1000 # r1 <= r2 +1000
(3)direct addressing
主記憶のアドレスを直接指定
(3-1) register
load r1,(r2) # r1 <= mem[r2]
主記憶のアドレスを保持するレジスタを指定する
(3-2) immediate
load r1,(1000) # r1 <= mem[1000]
主記憶のアドレスを直接指定する
(3-3)index
load r1,24(r2) # r1 <= mem[r2+24]
レジスタとオフセットで指定
(4)indirect addressing(間接参照)
(4-1)register
load r1,@(r2) # r1 <= mem[mem[r2]]
(4-2) immediate
load r1,@(1000) # r1 <= mem[1000]
(4-3) index
load r1,@24(r2) # r1 <= mem[mem[r2+24]]
2.4 RISC(reduced instruction set computer)
命令セットアーキテクチャの1カテゴリ。明確な定義はないが、一般的に次のような特徴を有するものがRISCと呼ばれる。
lw $1,4($2) add $1,$1,1 sw $1,4($2)などという形で書かなければいけない。
RISCの方針
命令を単純化して、命令数は増加しても命令当りの処理時間を短くすることで、全体jの処理を高速化する。(また、命令形式が単純であることはパイプライン処理のし易さにも影響する)
処理時間 = (命令数)*(命令あたりの処理時間)
このあたりは、後でパイプラインやらないと分からないかも
3.データパスと制御論理
データパス(data path)
所望の処理を実現するためのデータが流れる経路
制御論理
所望の処理を実現するために、データパス上のデータ転送を制御する論理。データパス上のタイミング制御も含む
有限状態機械(Finite State Machine)で表現することが多い
実現方法:wired logic(有線論理)→FFと組合せ回路
3.1データパス
(1)構成要素
演算器、マルチプレクサ、レジスタ、メモリ
(1-1)演算器:複数の入力に対し、制御信号で指定される演算を行う。
(1-2)マルチプレクサ
複数の入力に対して、制御信号で指定された入力を選択して出力(selecter)
(1-3)レジスタ:記憶部 機能的にはD-FFと類似だが、N-bitデータを扱う。制御信号(write enable)がある。MIPSの場合は32bit
(1-4)レジスタファイル
M個のレジスタを扱う。入力出力をどれだけ許すか?
最低、2入力1出力(そうじゃなきゃ演算ができないから)
3.2制御論理
所望の動作をデータパス上で実現するための論理
(1)wired logic(布線論理)による方法。ハードウェア(FFと組み合わせ回路)で実現
高速だが設計は大変
(2)マイクロプログラムによる方法。命令より一段下のレベルのマイクロ命令によってプログラム的に記述。
設計変更は容易だが、低速
3.3データパスと制御論理の設計
「全ての命令の動作を実現するハードウェア」
(1)各命令の実行ステージの分割
いくつ? 各ステージの動作は?
ステージ:1サイクルに対応
(2)前項を満たすデータパスの構築
該当するデータパス上で、各ステージの動作を実現する制御論理の仕様を、状態遷移図で表す。
(3)データパスはゲートレベルスイッチで対応
制御論理は状態遷移図で与えられているので、前述の二つの方法を用いて落としこむ。
1,2レジスタトランスファレベル設計
6/2
4.メモリシステム
4.1 キャッシュメモリ
4.1.1 概念
キャッシュ:大切なものを隠しておく場所
方針:高速かつ大容量な記憶装置が手に入ればいいのだが、一般的に高速な記憶装置ほど高価で、容量も少なくなる。そのため、プロセッサに"近い"場所に高速だが容量の小さいメモリを配置することで処理の高速化を図る。
根拠:局所性(locality)
時間的局所性
ある情報が参照されると、すぐ後にまた参照される傾向がある。
空間的局所性
ある情報が参照されると、近くの情報も参照される傾向がある。
高速化
キャッシュをどう構成させるか?
4.1.2 主記憶とキャッシュのアドレスマッピング
メモリからキャッシュへ持ってきたデータをどう配置するか?
(1)direct mapping(ダイレクトマップ方式)
主記憶のコピーの格納場所は、キャッシュ上で一意に定まる。
(2)fully associative(フルアソシアティブ)
主記憶のコピーの格納場所はキャッシュ上の任意の場所
(3)N-way set associative(n-ウェイセットアソシアティブ)
主記憶のコピーの格納場所は、キャッシュ上でN通りある。
キャッシュ上でデータを探す時間とキャッシュの使い易さのトレードオフ
4.1.3 キャッシュの構成と制御(p21)
(1) ダイレクトマップの例
ブロックサイズ4B,容量4KB
(1-1)キャッシュの構成
ブロック数:1024
ブロックのデータ部:4B
index:キャッシュブロック番号
V:当該ブロックが有効かどうか?
tag:当該ブロックに格納されているデータのアドレス
data:当該ブロックに格納されているデータの本体
(1-2)メモリ参照時のアドレスビットの意味
32bitのアドレス空間
offset部:アドレスの下位2bit[1:0]
→ブロック内のオフセットを定める
index部:アドレスの次の下位10bit[11:2]
→参照すべきcache indexを定める
tag部:上位20bit[31:12]
→tag部と比較される
(1-3)読み出しと参照の動作
(1)参照すべきアドレスのindex部からcache index を決定し、tagを参照
(2)キャッシュ内のtag部と、参照すべきアドレスのtag部が一致するかを比較
(3)キャッシュヒット時
キャッシュのデータ部から所望のデータを読みだす
キャッシュミス時
主記憶にデータを読みにいく
4.2.仮想記憶(virtual memory)
4.2.1 概要
物理的には小容量しかないメモリを仮想的に大容量のメモリとして提供する方法
OSの管理下で、ハードウェア機能のサポートにより限られた容量の主記憶と、大容量の2次記憶からなるメモリ階層構成において、大容量の主記憶を仮想的に(論理的に)実現
○ キャッシュ 仮想記憶
制御単位 ブロック(固定、32Bから256B) ページ(固定:4KBから) セグメント(可変)
入れ替え制御 ハード ソフト
(1)原理
主記憶の記憶領域が不足したら不要な主記憶の一部を2次記憶へ追い出し、主記憶上に新しい領域を確保する。
swap in : 2次記憶から主記憶へ
swap out: 主記憶から2次記憶へ
(2)アドレス空間
論理アドレス空間(logical address space)
ユーザプログラムが実行されているアドレス空間(仮想アドレス空間とも言う)
物理アドレス空間(physical address space)
主記憶上で実際に提供されているアドレス空間(実アドレス空間とも)
(3)制御の概略
1.PU上でメモリアクセス実行
2.論理アドレス→物理アドレスの変換(DAT:dynamic address translation)を変換表を用いて行なう。
3.変換可能→物理アドレスを用いて主記憶アクセス
変換不可→該当論理アドレスは主記憶にない。
→割り込み発生(ページフォールト)
→OSに制御が渡る→OSがswap in/out を行なう。
4.2.2 アドレス変換方式
アドレス変換の単位:ページ(固定) / セグメント(可変)
(1)ページング(paging)
1953(英マンチェスター大)
プリント22p
(2)セグメンテーション
1961(米Burroughs社)
主記憶に置く単位をプログラムの論理的に独立した単位(セグメント)とする方式。セグフォの名前はここから来ている。
ページングとの違いは多きさが可変であること
5.入出力制御
5.1 入出力制御方式
1.特別なI/O方式
アドレスとは別
2.address mapping I/O
あるアドレスへの読み書きを入出力として扱う。
5.1.2 入出力装置からの通知検出方法
1.ポーリング方式
CPUが定期的にI/Oデバイスを監視する。頻度が高ければ応答性も良くなるが、監視のオーバーヘッドも増加
2.割り込み方式(次でまたやる)
デバイス手動で、終了を割り込みで通知する。
割り込みを(ハードウェアが)検出すると、OSへ制御を渡して割り込み処理を行う。
ポーリングとは逆に、監視のオーバーヘッドは無いが、プロセスの切り替えに時間が必要
。
5.1.3 データ転送を行う主体による分類
(1) プログラム制御方式
CPUがプログラムモードの入出力命令によって、入出力装置を起動。
入出力命令実行中はCPU動作が中断するため、大量のデータ転送時はシステムの効率低下。(それゆえ、あまり使われない)
(2) DMA制御方式(direct memory access)
CPUとは独立に、主記憶と入出力装置のデータ転送を行う機構。CPUは入出力処理からは解放される。
(step1) CPUは入出力装置のID、実行すべき処理、転送先/元の開始アドレス、転送量をDMAに通知。DMAの起動(DMA kick)
(step2) DMAはバスの調停と入出力装置における処理を開始
(step3) DMA転送が終了したら割り込みで通知
例題. ポーリングと割り込み 一回のポーリングに400サイクル、CPU 500MHz 4words(16B毎)転送が行われ転送性能 4MB/sec のディスク データが失われないようにポーリングで検出する場合のポーリングのオーバヘッドは?
解. (1) 必要なポーリングの頻度 4MB/16B = 250k(回/sec) 1秒あたりのオーバヘッドは 400 * 250k = 100Mサイクル 100M/500M = 20% のオーバーヘッド (2) 割り込みの場合 一回の割り込み処理に、500サイクル要する場合 オーバーヘッドは? 割り込み頻度はポーリングと同じく250k オーバーヘッドは (250k * 500サイクル)/500Mサイクル = 25% (3) ディスクの入出力処理は全体の5%だけである場合 (3.1)ポーリング 変わらず 20% (3.2)割り込み 0.25 * 0.5 = 1.25(%) (4)DMA転送のオーバーヘッド 同じディスク DMA転送のsetupに1000サイクル DMA転送の終了の割り込みに5000サイクル 平均転送サイズ 8KB このときのオーバーヘッド ディスクは100%active 4MB/8KB = 0.5k(回/sec) 1回のDMA転送のオーバーヘッド 6000サイクル (6000 * 0.5)/500M = 0.6%
5.2 割り込み
不定期に起こる事象に対して、プログラムの実行を中断してしかるべき処理をすること。
5.2.1 割り込みの種類
precise/imprecise 正確な割り込み(復帰再開可能) 不正確な割り込み(復帰再開不可能)
5.2.2 // 6/30
5.2.2 割り込み処理方式
割り込みの受付は命令単位
6.オペレーティングシステム(Operating system)
ユーザとハードウェアシステムのインターフェイス
=ハードウェアの仮想化
6.1 役割
→高信頼性が要求されるシステム(銀行のオンラインシステム)では重要
6.2 プロセス管理とスケジューリング
6.2.1 プロセス(process)
OSからハードウェア資源の割り当てを受けて処理を実行しているプログラム。
(Linuxだとpsコマンド、Windowsではタスクマネージャで見られる)
6.2.2 プロセヌの状態と遷移
(1)プロセスの状態
図が書けねー
・遷移状態
1.初期状態:新しいプロセスが生成されると実行可能状態に
2.実行可能状態→実行状態
CPU資源が空いた時にスケジューリングアルゴリズムに従って、1つのプロセヌが選択され、CPU資源を割り当てる。
3.実行状態→実行可能状態
特定のプロセスがCPU資源を占有するのを避けるために、あらかじめ決められた時間(タイムスライス)を実行状態プロセスに割り当てタイムスライス終了時に実行可能状態に遷移(タイマ割り込み)
・プロセスの管理と切り替え
OS内では、
プロセヌ切り替え時に必要な処理
再開に必要な処理の退避
CPU資源内にあるプロセスの情報、プログラムカウンタ、レジスタの値は必須
6.2.3 スケジューリングアルゴリズム
スケジューリング
今回はCPUスケジューリング
スケジューラの評価基準
7.フォールトトレラントシステム
障害に対して強いシステム
7.2 評価尺度
応用分野によって必要となる信頼性は異なる。趣味の自宅鯖だったらいくら落ちても問題ないし、生命に関わるシステムだったら高い信頼性が必要。
例えば、何十年も宇宙にあって簡単に修理のできない人工衛星だったら信頼性を高め、保守性は少し無視してもいい。飛行機だったら、最低限飛行中の20時間ほどの間に故障を起こさなければよく、修理をすれば良いとか。
7.2.1 フォールトカバレッジ(fault coverage)
対象とするフォールト集合が現実に起こりうるフォールト全体のどの程度を包含するか。
計算システムにおけるフォールトの分類
評価モデル
どういう故障が起こるかの抽象モデル~ 良いモデルは、カバレッジ大、検出に必要な時間やコストが低い
7.2.2 信頼度(rliability)
障害発生を統計的分析を持つ確率事象として扱う。
f(t) 障害が生じる確率密度関数
時刻tからt+dtの間に障害が生じる確率はf(t)dt
0からtの間のtauで障害が発生する確率F(t)
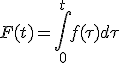
逆に時刻tまで障害が発生しない確率は
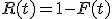
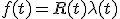
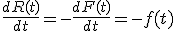
変数分離で積分すると
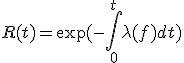
平均寿命 MTTF(mean time to failure)
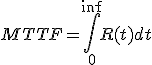
lambda(t)はどんな関数?
システムのハードウェア バスタブ曲線(経験則)