![[PukiWiki]](image/pukiwiki.png "[PukiWiki]")
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <time.h>
#define COUNT 41
#define TIMES 10000
#define SFMT_MEXP 19937
#define HAVE_SSE2 1
#include "dSFMT.c"
double calc_kai2(double kimu[4],int dat[4]);
void gennum(int cnt,double kimu_prob[4],int gen[4]);
//A O B AB
int main(void){
//帰無仮説の確率
double kimu_prob[4]={0.4,0.3,0.2,0.1};
double kimu[4];
//genは演算用、realに実際の教室での人数が入る
int gen[4],real[4]={13,12,12,4};
//TIMES(試行)回数分χ2乗値を格納する
double kai2s[TIMES],kai2,prob_big;
int i,bigger_cnt;
int seed=(unsigned) time(NULL);
init_gen_rand(seed);
for(i=0;i<4;i++){
kimu[i]=COUNT*kimu_prob[i];
}
printf("kr0:%f\n",kimu[0]);
kai2=calc_kai2(kimu,real);
printf("kai2:%f\n",kai2);
for(i=0;i<TIMES;i++){
gennum(COUNT,kimu_prob,gen);
kai2s[i]=calc_kai2(kimu,gen);
//printf("%f\n",kai2s[i]);
}
bigger_cnt=0;
for(i=0;i<TIMES;i++){
if(kai2<kai2s[i]){
bigger_cnt++;
}
}
prob_big=(double)(bigger_cnt)/TIMES;
printf("prob_big:%f\n",prob_big);
return 0;
}
double calc_kai2(double kimu[4],int dat[4]){
int i;
double kai2;
kai2=0;
for(i=0;i<4;i++){
kai2+=(dat[i]-kimu[i])*(dat[i]-kimu[i])/kimu[i];
}
return kai2;
}
void gennum(int cnt,double kimu_prob[4],int gen[4]){
int i,j,chk;
double conv,rnum;
for(i=0;i<4;i++){
gen[i]=0;
}
for(i=0;i<cnt;i++){
rnum=genrand_close_open();
conv=0;
for(j=0;j<4;j++){
conv+=kimu_prob[j];
if(rnum<conv){
gen[j]++;
//printf("%d\t%d\t%f\t%f\n",i,j,rnum,conv);
break;
}
if(j==3){
//ありえない場合
printf("error:%d\t%d\t%f\t%f\n",i,j,rnum,conv);
}
}
}
chk=0;
for(j=0;j<4;j++){
chk+=gen[j];
}
if(chk!=cnt){
//ありえない場合
printf("error:%d\t",chk);
}
}尤度について
L=41!/(a!b!c!d!) *(a/n)^a*(b/n)^b*(c/n)^c*(d/n)^d
とした式をカイ二乗統計量の代わりに用いる。
後はif文中の kai2>kai2s を \lambda=(定数)と設定し、 \lambdaを調整して(多分\lambda=1でいいと思います) (\lambda)*kai2<kai2s とすれば尤度のほうもできると思われます。
導出過程は添付ファイルを見てください。
そ、そうなの?…尤度比検定統計量
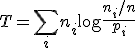
を使えばいいのでは?それとも
L=41!/(a!b!c!d!) *(Pa)^a*(Po)^b*(Pb)^c*(Pab)^d
ならかなり近い値になるかも? by tako